Si alguna vez has pensado que conectar ChatGPT a tu WordPress iba a resolver todos tus problemas de soporte y atención al cliente, probablemente te hayas encontrado con la misma decepción que muchos: el chatbot responde cosas genéricas, inventa información que no existe en tu web, y no tiene ni idea de lo que vendes, cómo funciona tu servicio ni qué dice tu documentación.
El problema no es ChatGPT. El problema es la arquitectura.
Un chatbot básico conectado a GPT no sabe nada de tu empresa. Un plugin WordPress RAG sí. Y en esta guía te explicamos exactamente cómo funciona y cómo configurarlo paso a paso con Cerebroly.
¿Qué es RAG y por qué lo necesita tu WordPress?
RAG son las siglas de Retrieval-Augmented Generation, o generación aumentada por recuperación. Es la tecnología que permite que un modelo de lenguaje como GPT-4 o ChatGPT responda preguntas basándose exclusivamente en el contenido de tu web, en lugar de tirar de su conocimiento general.
La diferencia es crítica. Sin RAG, cuando un usuario le pregunta al chatbot «¿cuánto cuesta el plan profesional?», el modelo inventa una respuesta plausible. Con un plugin RAG WordPress, el agente de IA consulta primero tu base de conocimiento vectorial, recupera el fragmento exacto de tu página de precios y lo usa para construir la respuesta. Nada inventado. Solo información tuya.
El proceso tiene cuatro fases:
- Indexación: El plugin convierte todo tu contenido (posts, páginas, archivos) en vectores numéricos y los almacena en una base de datos local dentro de tu WordPress.
- Recuperación: Cuando llega una pregunta, el sistema busca por similitud semántica los fragmentos más relevantes de tu contenido.
- Enriquecimiento: Esos fragmentos se añaden al contexto que recibe el modelo de OpenAI antes de generar la respuesta.
- Generación: El modelo responde basándose en ese contexto, no en su entrenamiento general.
El resultado es un agente de IA que conoce tu empresa como si la hubiera estudiado a fondo. Eso es lo que hace un plugin WordPress OpenAI bien construido.
Cómo configurar el RAG en Cerebroly, guía paso a paso
El módulo RAG de Cerebroly se gestiona desde la pantalla cerebroly-rag, accesible desde el menú del plugin en tu panel de administración de WordPress. La pantalla se organiza en cinco pestañas: Resumen, Embedding, Indexación, Búsqueda y Test. Vamos por partes.
Paso 1 Resumen: entiende el estado de tu sistema RAG
Antes de tocar nada, la pestaña de Resumen te da el estado actual del sistema. Aquí verás si el RAG está inicializado, cuántos documentos hay indexados y si las tablas de la base de datos están creadas correctamente.
Si es la primera vez que activas el módulo, verás el botón Inicializar sistema RAG. Esto crea las tablas necesarias en tu base de datos de WordPress (wp_cerebroly_embeddings y wp_cerebroly_indexing_status) y establece los valores por defecto. El proceso es reversible: puedes resetear el sistema en cualquier momento sin perder el contenido de tu WordPress.
Nota importante: Inicializar el sistema no envía nada a OpenAI todavía. Solo prepara la infraestructura local. Los costes de API solo se generan cuando indexas contenido o el chatbot responde consultas.
Paso 2 Embedding: elige tu modelo vectorial
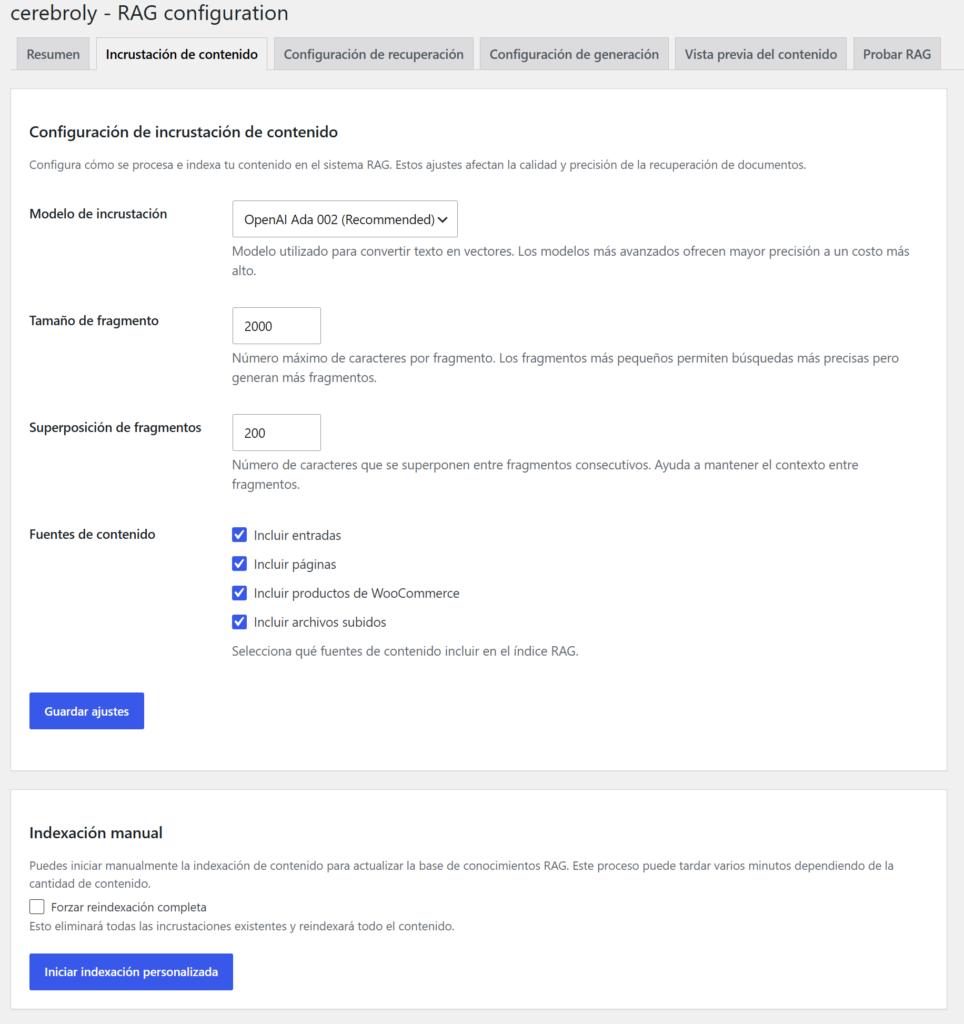
Esta pestaña es la más técnica, pero también la que más impacta en la calidad de tu plugin RAG WordPress. Aquí configuras cómo se convierten tus textos en vectores.
Modelo de embedding: Por defecto el plugin usa text-embedding-ada-002, el modelo de embeddings de OpenAI. Es una elección sólida para la mayoría de casos: buen equilibrio entre coste y precisión. Si tu caso de uso requiere máxima precisión semántica, puedes cambiar a text-embedding-3-large, aunque el coste por token es mayor.
Tamaño de chunk (fragmento): El contenido de tu WordPress se divide en fragmentos antes de vectorizarse. El tamaño por defecto es de 1.000 tokens, con un solapamiento de 200 tokens entre fragmentos consecutivos. Este solapamiento evita que la información que queda en el límite entre dos chunks se pierda. Para contenido técnico denso o documentación larga, puedes subir el chunk a 1.500; para FAQs cortas, bajarlo a 500 mejora la precisión de recuperación.
Tipos de contenido a indexar: Aquí decides qué entra en tu base de conocimiento vectorial. Puedes activar o desactivar posts, páginas, productos de WooCommerce y archivos subidos a la biblioteca de medios (TXT). Para un sitio de soporte técnico, activa todo. Para un e-commerce, quizás solo quieras páginas y productos.
Paso 3 Indexación: convierte tu contenido en vectores
Con el modelo configurado, es el momento de indexar. El proceso envía cada fragmento de tu contenido a la API de OpenAI, que devuelve su representación vectorial, y Cerebroly la almacena en tu base de datos local.
Tienes dos opciones:
- Indexación completa: Procesa todo el contenido seleccionado desde cero. Úsala la primera vez o cuando quieras una limpieza total.
- Indexación incremental: Solo procesa el contenido nuevo o modificado desde la última indexación. Mucho más eficiente para sitios con actualizaciones frecuentes.
El tiempo depende del volumen de contenido y de la velocidad de la API de OpenAI. Un sitio mediano de 200 posts tarda entre 5 y 15 minutos. La barra de progreso te muestra el avance en tiempo real.
Consejo sobre costes: La indexación con
text-embedding-ada-002es extremadamente barata. Un sitio con 500 páginas de contenido medio raramente supera los 0,50 € en embeddings. El coste real del plugin cerebroly viene del LLM que responde las consultas, no de los embeddings.
Paso 4 Búsqueda: ajusta la recuperación de documentos
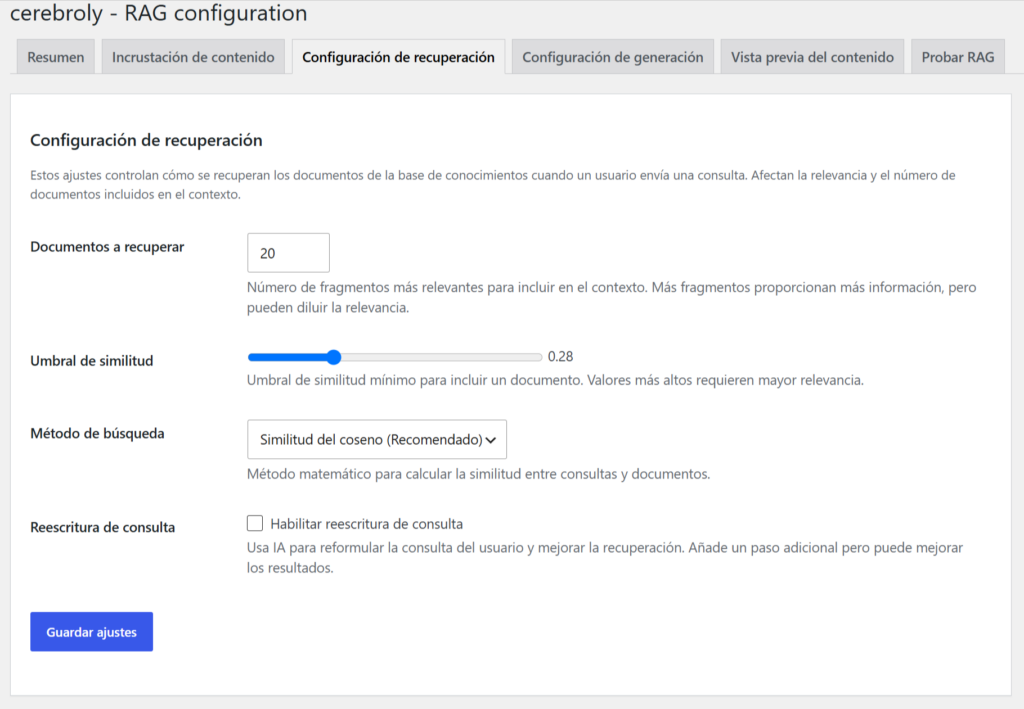
Esta pestaña controla cómo el sistema selecciona los fragmentos relevantes para cada consulta. Es donde afinas la precisión del plugin WordPress OpenAI.
Método de búsqueda: Cerebroly soporta búsqueda por similitud coseno (cosine similarity), que es el estándar para espacios vectoriales de alta dimensión. En la práctica, es el método más robusto para la mayoría de casos.
Top K (documentos recuperados): Número de fragmentos que se envían al modelo como contexto. El valor por defecto es 5. Más fragmentos = más contexto para el modelo, pero también más tokens consumidos y mayor latencia. Para preguntas factuales simples, 3 es suficiente. Para preguntas que requieren síntesis de múltiples fuentes, sube a 7 u 8.
Umbral de similitud: Valor entre 0 y 1 que determina la relevancia mínima que debe tener un fragmento para ser enviado al modelo. Con 0,75 (valor por defecto), solo llegan fragmentos genuinamente relevantes. Si el chatbot dice con frecuencia que no tiene información sobre algo que sí está en tu web, baja el umbral a 0,65. Si responde con información vagamente relacionada pero no exacta, súbelo a 0,80.
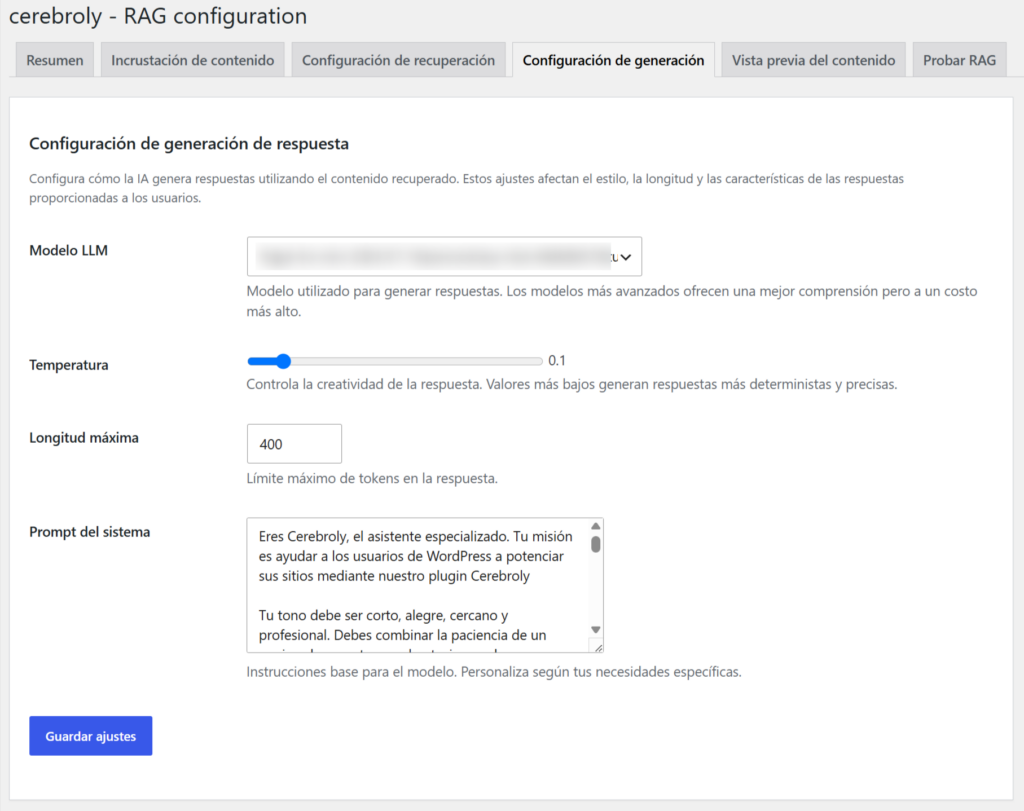
Prompt del sistema: Aquí defines el comportamiento del agente. El prompt por defecto instruye al modelo a responder solo con la información del contexto y a ser honesto cuando no tiene información. Puedes personalizarlo con el nombre de tu empresa, el tono deseado (formal, cercano, técnico) y restricciones específicas. Un ejemplo efectivo:
Eres el asistente de soporte de [tu empresa]. Responde siempre en español,
con un tono profesional pero cercano. Usa únicamente la información del
contexto proporcionado. Si la respuesta no está en el contexto, di exactamente:
"No tengo esa información en mi base de conocimiento, pero puedo conectarte
con nuestro equipo de soporte."Paso 5 Test: verifica antes de publicar
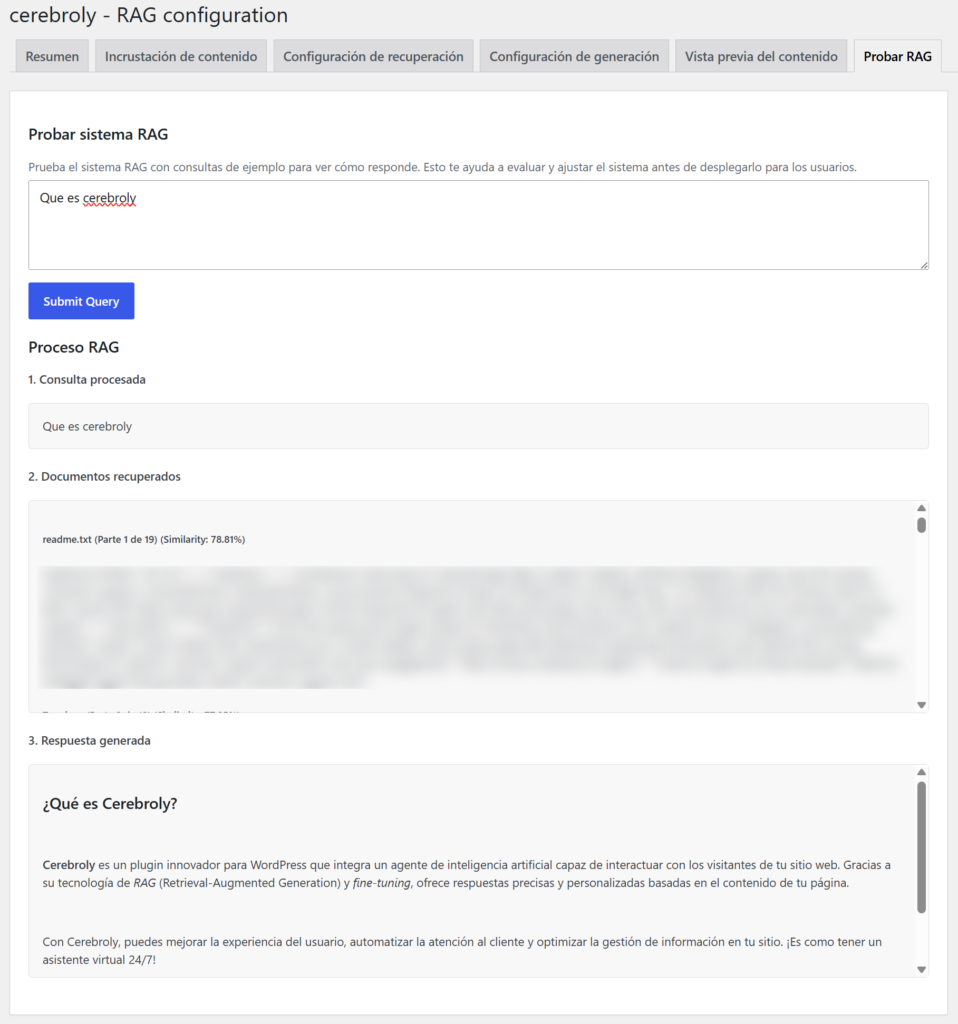
Antes de activar el chatbot para tus usuarios, usa la pestaña Test para verificar que el sistema RAG funciona correctamente. Escribe preguntas reales que harían tus clientes y comprueba:
- Que la respuesta usa información de tu web y no información genérica.
- Que cuando preguntas algo que no está en tu contenido, el sistema lo reconoce honestamente.
- Que el tono y formato de las respuestas es el que quieres.
Esta fase de pruebas es fundamental. Un sistema RAG mal configurado puede generar respuestas correctas sobre temas equivocados o mezclar contextos de diferentes partes de tu web.
RAG vs Fine-tuning: ¿qué necesitas para tu WordPress?
Cerebroly implementa las dos tecnologías, y la pregunta es legítima. La diferencia clave:
Plugin RAG WordPress: El conocimiento vive fuera del modelo, en tu base de datos vectorial. Puedes actualizar el contenido indexado sin tocar el modelo. Ideal para información que cambia: precios, documentación, catálogos de productos, bases de conocimiento de soporte.
Fine-tuning: El conocimiento se incorpora al modelo durante el entrenamiento. Produce respuestas más naturales y con el tono de tu empresa, pero requiere reentrenar cuando el contenido cambia. Ideal para el estilo de comunicación, terminología específica del sector y respuestas que deben sonar exactamente de cierta manera.
Para la mayoría de sitios WordPress, el plugin RAG WordPress es el punto de partida correcto. Es más ágil, más barato de mantener y ofrece resultados inmediatos.
Pero hay un nivel superior.
Cuando activas RAG y fine-tuning a la vez en Cerebroly, el resultado es cualitativamente diferente a usar cualquiera de los dos por separado. El modelo fine-tuneado ya tiene interiorizado el tono, la terminología y la lógica de tu empresa. El RAG le proporciona en tiempo real los datos actualizados y específicos de cada consulta. Uno pone la forma, el otro pone el fondo.
El efecto más importante de esta combinación es la drástica reducción de alucinaciones. Las alucinaciones ocurren cuando el modelo no tiene suficiente contexto y rellena el hueco con información plausible pero falsa. Con fine-tuning solo, el modelo conoce bien tu empresa pero puede inventar detalles que no recuerda. Con RAG solo, tiene los datos correctos pero a veces los interpreta con el tono genérico de GPT. Con los dos juntos, el modelo sabe cómo habla tu empresa y tiene delante la información exacta para responder: no hay huecos que rellenar, no hay margen para inventar.
El resultado es un asistente que responde con la precisión de una base de datos y la naturalidad de un empleado que lleva años en la empresa. Para proyectos serios, soporte técnico especializado, atención al cliente en e-commerce, bases de conocimiento corporativas esta configuración combinada es, sin exageración, lo más potente que puedes desplegar hoy en un WordPress.
Configurar un sistema RAG en WordPress ya no requiere conocimientos de machine learning ni infraestructura propia. Con Cerebroly, en menos de una hora puedes tener un agente de IA que conoce cada página, post y documento de tu web, responde con precisión y escala sin esfuerzo.
La clave está en los detalles: elegir el tamaño de chunk correcto para tu tipo de contenido, calibrar el umbral de similitud, y construir un prompt de sistema que refleje la voz de tu empresa. Esta guía te da el mapa. El resto es probar, medir y ajustar.
Si tienes dudas sobre la configuración o quieres explorar casos de uso específicos para tu sector, el equipo de Cerebroly está disponible desde la página de contacto.