La página cerebroly-fine-tuning es donde ocurre la magia más profunda del plugin. Si la pantalla de ajustes es el panel de control del agente de IA, el módulo de fine-tuning es el taller donde construís el motor. Aquí es donde vuestro contenido de WordPress deja de ser texto en una base de datos y se convierte en el conocimiento entrenado de un modelo de lenguaje que habla con la voz de vuestra empresa.
Hay un momento que siempre recordamos cuando configuramos el primer fine-tuning en Cerebroly: ver cómo el modelo respondía con terminología exacta del cliente, con su tono, con sus matices. No era ChatGPT genérico. Era algo diferente. Era el GPT personalizado de esa empresa. Eso es lo que construís aquí.
La pantalla se organiza en cuatro pestañas: Resumen, Editor de datos, Vista previa y Entrenamiento. Cada una cubre una fase del proceso. Os lo explicamos todo.
Pestaña resumen, el estado de tu modelo de ajuste fino
La primera pestaña es el punto de partida. Os da una visión de conjunto antes de tocar nada.
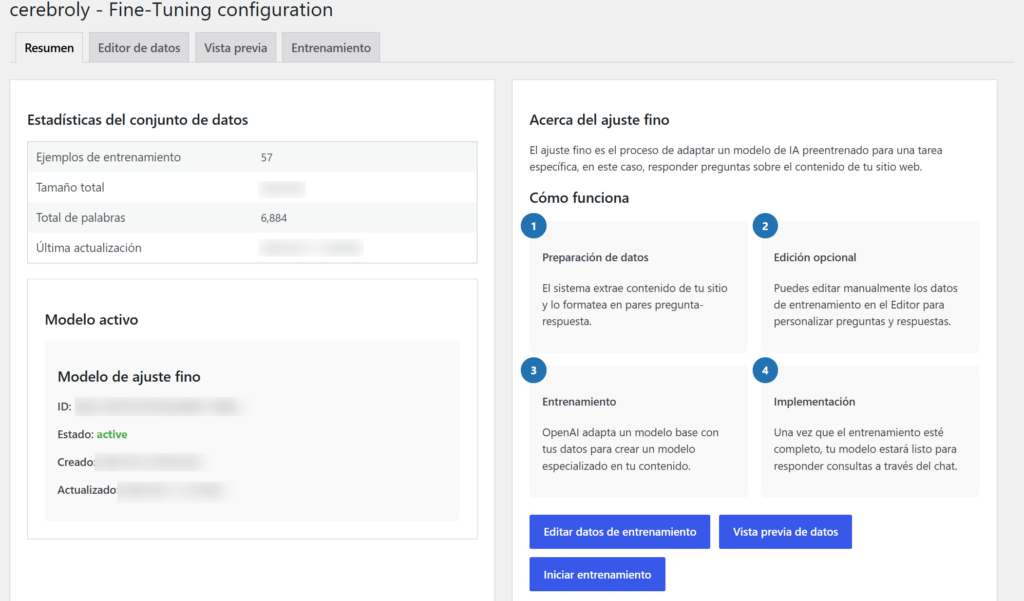
A la izquierda encontráis las estadísticas del conjunto de datos: número de ejemplos de entrenamiento generados, tamaño total del archivo, total de palabras procesadas y fecha de última actualización. Con el contenido de una web mediana podéis tener fácilmente entre 40 y 100 ejemplos generados automáticamente. En las pruebas internas llegamos a 57 ejemplos con 6.884 palabras para un sitio de documentación, y el modelo resultante era notablemente más preciso que el base.
A la derecha, si ya habéis completado algún entrenamiento, aparece la tarjeta Modelo activo. Muestra el ID del modelo fine-tuned, su estado (active, pending, failed), la fecha de creación y la fecha de última actualización. Ese ID con el sufijo wp-chat-[hash] es vuestro modelo. Nadie más lo tiene. Es literalmente un GPT personalizado creado a partir del contenido de vuestro WordPress.
También en esta pestaña encontráis el resumen del proceso de fine-tuning en cuatro pasos: preparación de datos, edición opcional, entrenamiento y activación. Es la hoja de ruta. Los detalles están en las otras tres pestañas.
Nota del equipo: Si ya tenéis un modelo activo, podéis iniciar un nuevo entrenamiento sin interrumpir el servicio. El modelo anterior sigue activo hasta que el nuevo esté listo y lo activéis manualmente.
Pestaña editor de datos, el dataset de entrenamiento en vuestras manos
Aquí está la diferencia real entre Cerebroly y cualquier otro plugin de IA para WordPress que simplemente «conecta con ChatGPT».
El plugin genera automáticamente un dataset de entrenamiento en formato JSONL a partir de vuestro contenido publicado: posts, páginas y archivos subidos. Cada entrada del dataset es un objeto con el array messages, que contiene un mensaje de rol user con la pregunta y un mensaje de rol assistant con la respuesta ideal. Es exactamente el formato que requiere la API de fine-tuning de OpenAI.
json
{
"messages": [
{ "role": "user", "content": "¿Qué es el ajuste fino?" },
{ "role": "assistant", "content": "El ajuste fino es el proceso de adaptar un modelo..." }
]
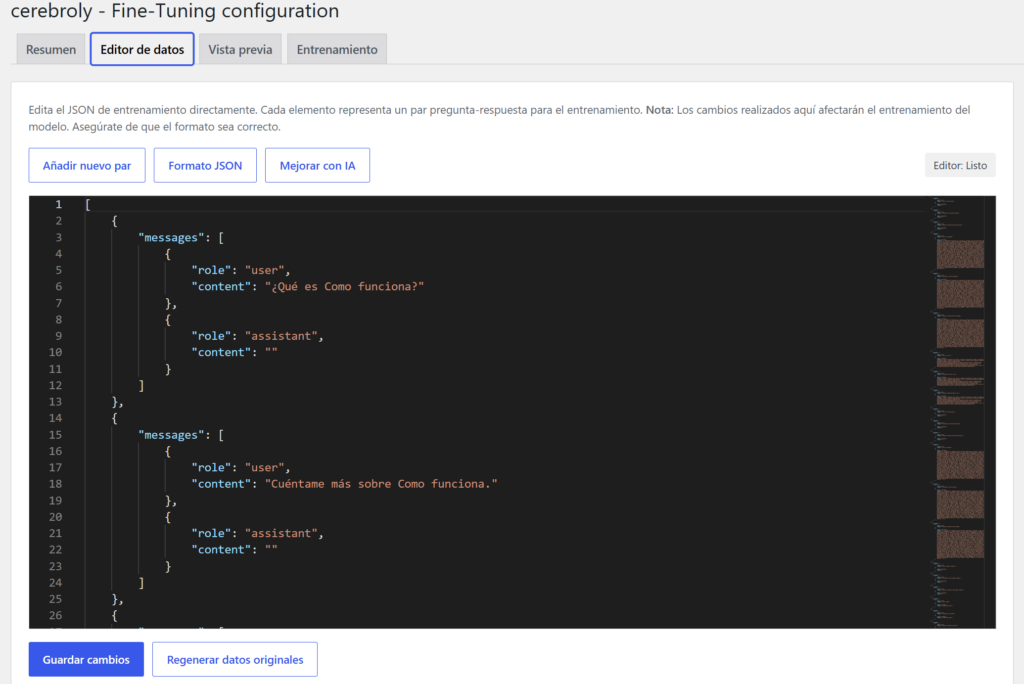
}El editor que usamos para esto es Monaco Editor, el mismo motor que VS Code. Sintaxis resaltada, números de línea, validación de esquema JSON en tiempo real, minimap lateral. Si escribís mal un campo o dejáis una coma de más, el editor os lo marca antes de que intentéis guardar.
Tenéis tres botones en la barra de herramientas:
Añadir nuevo par: Inserta una nueva entrada vacía al final del dataset. Útil para añadir a mano preguntas frecuentes que no están en el contenido publicado, casos edge que sabéis que vuestros usuarios preguntan, o respuestas con el tono exacto que queréis que tenga el asistente.
Formato JSON: Reindenta y ordena todo el JSON con un clic. Imprescindible si habéis editado a mano y el formato ha quedado irregular.
Mejorar con IA: Este es el favorito del equipo. Llama a la API de OpenAI para que el propio modelo analice vuestro dataset actual y genere variaciones y preguntas alternativas para cada ejemplo. El resultado es un dataset más rico, más natural, con más formas de hacer la misma pregunta. Consume tokens adicionales, pero la diferencia en la calidad del modelo entrenado es clara. Para proyectos profesionales, activadlo siempre.
En la parte inferior hay dos botones más: Guardar cambios y Regenerar datos originales. Este último es vuestro botón de pánico si habéis editado demasiado y queréis volver al dataset generado automáticamente desde el contenido.
Pestaña vista previa, verifica antes de entrenar
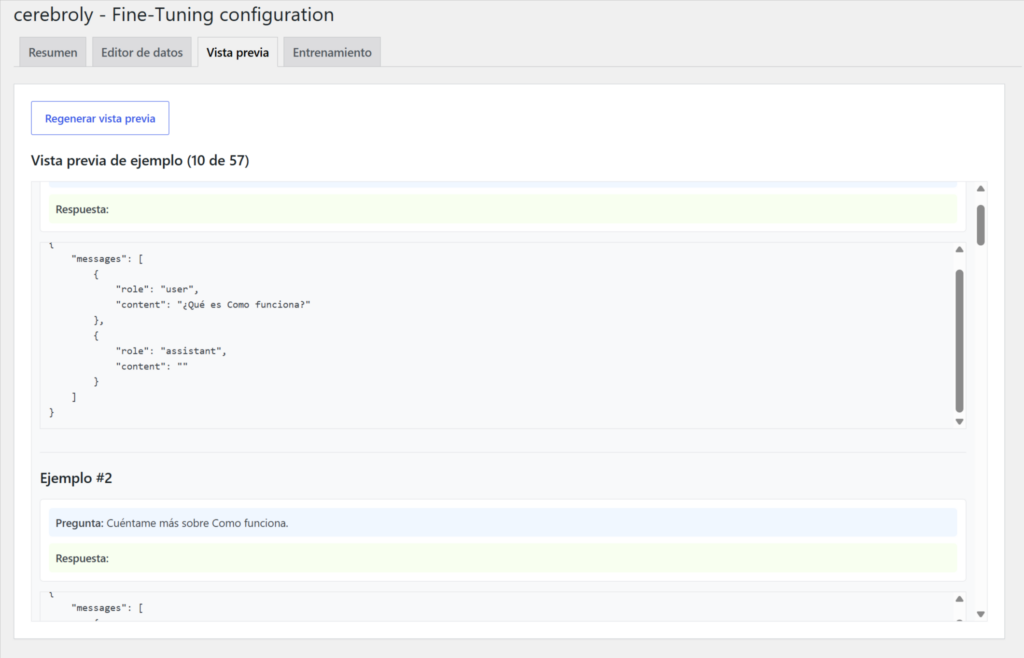
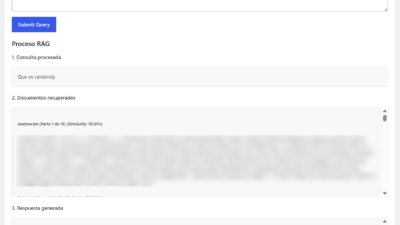
Antes de enviar nada a OpenAI, la pestaña de Vista previa os muestra exactamente qué contiene vuestro dataset en formato legible. No el JSON crudo del editor, sino una presentación amigable: cada ejemplo con su pregunta resaltada en azul y su respuesta en verde, numerados del 1 al N.
El número entre paréntesis del título (Vista previa de ejemplo (10 de 57)) indica cuántos ejemplos se están mostrando y cuántos tiene el dataset total. Por defecto se muestran los primeros diez para no sobrecargar la pantalla.
El botón Regenerar vista previa actualiza la visualización si habéis guardado cambios en el editor y queréis ver cómo quedan antes de continuar.
Esta pestaña es importante porque es el último control de calidad antes del entrenamiento. Revisadla siempre. Es el momento de detectar ejemplos con respuestas vacías como el que vemos en las capturas con "content": "" que son datos de baja calidad que degradarán el modelo. Si encontráis entradas vacías, volved al editor, completadlas o eliminadlas.
Consejo: Un dataset pequeño y bien curado siempre supera a un dataset grande con ruido. Mejor 30 ejemplos excelentes que 100 a medias. El fine-tuning de IA amplifica lo que le dáis: si el dataset es bueno, el modelo es bueno; si tiene basura, el modelo la aprende.
Pestaña entrenamiento, lanzar el proceso de ajuste fino
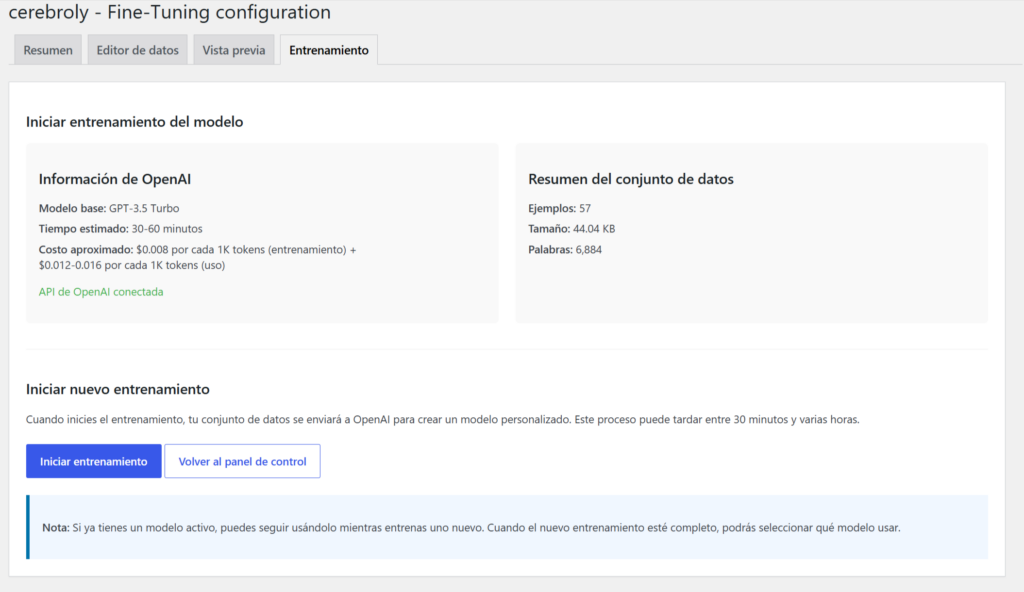
La pestaña de Entrenamiento es la recta final. Antes de hacer clic en el botón grande azul, el plugin os da toda la información que necesitáis para tomar una decisión informada.
En el bloque Información de OpenAI encontráis:
- Modelo base: GPT-3.5 Turbo por defecto, configurable desde la pantalla de ajustes. Podéis cambiarlo a GPT-4o mini u otros modelos compatibles con fine-tuning según vuestro presupuesto y necesidades de calidad.
- Tiempo estimado: Entre 30 y 60 minutos para datasets habituales. Puede ser más si el volumen es grande.
- Costo aproximado: El plugin os muestra la referencia de precios de OpenAI: $0.008 por cada 1K tokens de entrenamiento, más $0.012-$0.016 por cada 1K tokens en uso posterior. No hay sorpresas. Sabéis lo que vais a pagar antes de empezar.
- Estado de la API: Confirmación visual de que la API key de OpenAI está conectada y operativa.
En el bloque Resumen del conjunto de datos tenéis el número de ejemplos, el tamaño del archivo y las palabras totales del dataset que vais a enviar.
El botón Iniciar entrenamiento sube el archivo training_data.jsonl a la API de OpenAI, crea el job de fine-tuning en /fine_tuning/jobs y registra el proceso en la tabla wp_cerebroly_models de vuestra base de datos. A partir de ese momento, el estado se actualiza automáticamente vía webhook cuando OpenAI completa el proceso.
Hay una nota importante en esta pantalla que resume bien la filosofía del plugin: «Si ya tienes un modelo activo, puedes seguir usándolo mientras entrenas uno nuevo. Cuando el nuevo entrenamiento esté completo, podrás seleccionar qué modelo usar.» Sin interrupciones. Sin downtime. El agente de IA sigue trabajando mientras se forma la siguiente versión.
Cuándo usar fine-tuning y cuándo combinarlo con RAG
Esta es la pregunta que más nos hacen. La respuesta honesta es: depende del proyecto, pero la combinación es casi siempre la mejor opción.
El fine-tuning de IA aporta algo que el sistema RAG no puede dar por sí solo: el modelo aprende a comunicarse. Aprende vuestro tono, vuestra terminología técnica, la estructura de respuesta que queréis, las advertencias que debéis incluir, lo que podéis y no podéis decir. Eso queda grabado en el modelo y no requiere instrucciones adicionales en cada llamada.
El sistema RAG aporta información en tiempo real. Cada vez que publicáis una entrada nueva, actualizáis un precio o subís un documento, el RAG ya lo sabe. Sin reentrenar.
La arquitectura ideal para la mayoría de proyectos profesionales es tener ambos activos: RAG para la base de conocimientos dinámica, fine-tuning para el estilo de comunicación. El contexto recuperado por el RAG lo recibe un modelo que ya sabe cómo hablar con vuestros usuarios. Eso es lo que diferencia a un asistente genérico de un agente de IA que parece parte de la empresa.
Para sitios que cambian poco documentación técnica estable, catálogos cerrados, webs corporativas sin blog activo el fine-tuning solo puede ser suficiente. Para e-commerce, bases de conocimiento, soporte técnico con actualizaciones frecuentes: RAG + fine-tuning, siempre.
Cuántos ejemplos necesitáis para un buen fine-tuning
El mínimo técnico que impone la API de OpenAI son 3 ejemplos. El mínimo práctico para obtener un modelo que realmente haya aprendido algo es bastante más.
En nuestras pruebas, con entre 30 y 50 ejemplos de buena calidad ya se aprecia un cambio claro en el tono y la estructura de las respuestas. Con más de 100 el modelo empieza a ser sólidamente consistente. Con más de 200 ejemplos bien curados, el resultado es un asistente que parece haber trabajado en la empresa durante años.
Lo que más importa no es la cantidad sino la calidad de los pares pregunta-respuesta. Un ejemplo con una respuesta vacía o genérica no enseña nada, y puede introducir inconsistencias. Por eso el editor Monaco, la vista previa y el botón «Mejorar con IA» no son opcionales: son el proceso de control de calidad del entrenamiento.
El error más frecuente que vemos en implementaciones de fine-tuning WordPress es generar el dataset automáticamente, no revisarlo y lanzar el entrenamiento directamente. El modelo resultante hereda todos los problemas del dataset. Dedicad 20 minutos a revisar la vista previa. Siempre vale la pena.
El resultado, vuestro modelo activo en producción
Cuando OpenAI completa el job de entrenamiento, el webhook actualiza el estado en wp_cerebroly_models y el modelo aparece como active en la pestaña Resumen. A partir de ese momento, el chat de vuestra web ya no usa el modelo base de OpenAI: usa vuestro modelo. El que aprendió de vuestro contenido, con vuestro tono, para vuestros usuarios.
El ID del modelo algo como ft:gpt-3.5-turbo:wp-chat-a3f8b2c1 es el identificador de vuestro GPT personalizado en la infraestructura de OpenAI. Podéis tener varios modelos entrenados y elegir cuál usar. Si un entrenamiento sale mal, tenéis el anterior como respaldo.
Esta es la parte del producto de la que más orgullosos estamos en Cerebroly: el fine-tuning no es una feature oculta para usuarios avanzados. Es una pantalla con cuatro pestañas, un editor con validación en tiempo real, una vista previa clara y un botón de lanzamiento con toda la información antes de confirmar. Cualquier persona que gestione un WordPress puede entrenar su propio modelo de IA sin saber nada de machine learning.
¿Queréis empezar? Descargad Cerebroly en cerebroly.com e instaladlo en vuestro WordPress. La API key, el primer dataset y el primer entrenamiento os llevará menos de una hora.
¿Tienes dudas sobre el proceso de fine-tuning? Consulta también nuestra guía de configuración inicial del plugin para asegurarte de que la conexión con OpenAI está correctamente configurada antes de lanzar el entrenamiento.